這個 side project 是約 3 年前開始的,其中一個目的是想要了解搜尋過去重大新聞的可能性,一個就是對 Meilisearch 做壓力測試。
主要有幾點:
- 系統使用量非常彈性的工具
- Disk I/O 極大
- 一些好功能在商用授權,不確定什麼時候會 open source
簡報不含講稿,請閱讀空氣、通靈、留言討論。KaLUG 的分享會有額外的內容。
ps. LibreOffice 好難用 (/‵Д′)/~ ╧╧
這個 side project 是約 3 年前開始的,其中一個目的是想要了解搜尋過去重大新聞的可能性,一個就是對 Meilisearch 做壓力測試。
主要有幾點:
簡報不含講稿,請閱讀空氣、通靈、留言討論。KaLUG 的分享會有額外的內容。
ps. LibreOffice 好難用 (/‵Д′)/~ ╧╧
dust 發現 journal 佔了 4 GB … 現在儲存空間很貴的啊 QQ
systemd 會將自己的 log 放在 /var/log/journal 中,沒有特別設定的話,記錄會一直保留。
檢視 journal 使用佔用了多少儲存空間:
journalctl --disk-usage
清除舊的資料:
# 如果是清除 7 天前的資料,則可改為 7d journalctl --vacuum-time=3months
或是清除資料,僅保留 500 MB 的記錄:
journalctl --vacuum-size=500M
Arch Linux Wiki 中有更詳細的說明。
無意間發現 Laravel 在 public/index.php 有這樣一段:
define('LARAVEL_START', microtime(true));
這樣要取得程式執行時間就方便多了,不用做一些 workaround。
若要取得程式執行時間,可以這樣寫:
$elapsed = mocrotime(true) - LARAVEL_START;
懷疑某個 container 造成 disk IO busrt,拖累到其他服務:
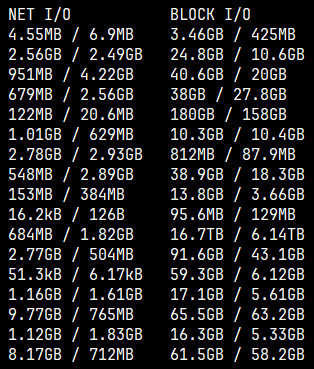
先透過 來降低 container 優先權觀察一陣子:
services:
app:
blkio_config:
# defalt = 500
weight: 100
看到新聞:ChatGPT 擊垮了 133 年信任傳統:普林斯頓大學廢除「無監考考試」,強制教授重回考場
這並不是 ChatGPT 和 AI 的問題,GenAI 推出之前難道就沒有考試作弊和作業代寫的問題嗎?如果所有學生都自重,決定只使用自己的能力來考試、寫作業,學校還需要擔心監考問題和作弊問題嗎?
覺得其實根本不是 AI 的問題,只是剛好 AI 目前是大家炒作話題,提高流量的關鍵字,說到底還是「人」的問題。
刀可以用來殺人,但是會個方式使用刀卻可以救人,像是動手術。
諾貝爾發明火藥,希望可以協助開鑿山洞,鋪設鐵路道路、促進貿易,但火藥卻被用在武器和戰爭。諾貝爾希望科技可以用在對人類有助益的方面,後來才會設立諾貝爾獎。
AI 技術,可以用來做詐騙,也可以像 AlphaFold 用來研究疾病協助藥物開發。
工具可以協助改變世界,但是往哪一個方向改變,最終還是取決於「人」將工具用來做什麼。