Bruno 和 Postman 的功能相同,但不用上網登入以後才能使用,這點蠻吸引我的。
在免費版本中,Bruno 可以建立 2 個 workspace,這點比 Postman 好一些。若付費購買授權 Bruno 也便宜一點。
另外 Bruno 有公開 source code 並使用 MIT 授權。
先來玩看看。
Bruno 和 Postman 的功能相同,但不用上網登入以後才能使用,這點蠻吸引我的。
在免費版本中,Bruno 可以建立 2 個 workspace,這點比 Postman 好一些。若付費購買授權 Bruno 也便宜一點。
另外 Bruno 有公開 source code 並使用 MIT 授權。
先來玩看看。
討論 HTTP 與 HTTPS 的優缺點前,先來了解瀏覽器和網頁伺服器之間是怎麼溝通的。
HTTP 的 request 主要包含幾個項目:
其中 URL 固定以明碼 (plain text) 傳輸,若使用 HTTPS 的話,header 和 body 內容會被加密。
URL 的內容會用於判斷 request 應該要由哪一台伺服器接收 (透過 domain 來判斷),HTTP methods 則用於判斷要如何與伺服器互動,另外還有 HTTP 傳輸協議的版本,例如要使用 HTTP 1.1 或是 2。
以下範例透過 curl 加上 -v 參數,連線至 http://blog.zeroplex.tw/2020/11/01/benfords-law/ 頁面,另外多加上一個 Origin 當作 header。
使用 HTTP (沒有加密) 時,curl 的動作:
curl --http2 --header "Origin: https://zeroplex.tw" -X GET http://blog.zeroplex.tw/2020/11/01/benfords-law/ -v
Note: Unnecessary use of -X or --request, GET is already inferred.
* Host blog.zeroplex.tw:80 was resolved.
* IPv6: (none)
* IPv4: 172.104.77.215
* Trying 172.104.77.215:80...
* Connected to blog.zeroplex.tw (172.104.77.215) port 80
> GET /2020/11/01/benfords-law/ HTTP/1.1
> Host: blog.zeroplex.tw
> User-Agent: curl/8.5.0
> Accept: */*
> Connection: Upgrade, HTTP2-Settings
> Upgrade: h2c
> HTTP2-Settings: AAMAAABkAAQAoAAAAAIAAAAA
> Origin: https://zeroplex.tw按照順序,curl 動作的順序如下:
blog.zeroplex.tw:80 was resolved:解析網域名稱,得知網站伺服器的 IP 為 172.104.77.215Connected to blog.zeroplex.tw (172.104.77.215):連線到伺服器> 的內容)嘛 …. 蠻簡單的。
再來看看使用 HTTPS (有加密) 時,流程上有什麼差異:
curl --http2 --header "Origin: https://zeroplex.tw" -X GET https://blog.zeroplex.tw/2020/11/01/benfords-law/ -v
Note: Unnecessary use of -X or --request, GET is already inferred.
* Host blog.zeroplex.tw:443 was resolved.
* IPv6: (none)
* IPv4: 172.104.77.215
* Trying 172.104.77.215:443...
* Connected to blog.zeroplex.tw (172.104.77.215) port 443
* ALPN: curl offers h2,http/1.1
* TLSv1.3 (OUT), TLS handshake, Client hello (1):
* CAfile: /etc/ssl/certs/ca-certificates.crt
* CApath: /etc/ssl/certs
* TLSv1.3 (IN), TLS handshake, Server hello (2):
* TLSv1.3 (OUT), TLS change cipher, Change cipher spec (1):
* TLSv1.3 (OUT), TLS handshake, Client hello (1):
* TLSv1.3 (IN), TLS handshake, Server hello (2):
* TLSv1.3 (IN), TLS handshake, Encrypted Extensions (8):
* TLSv1.3 (IN), TLS handshake, Certificate (11):
* TLSv1.3 (IN), TLS handshake, CERT verify (15):
* TLSv1.3 (IN), TLS handshake, Finished (20):
* TLSv1.3 (OUT), TLS handshake, Finished (20):
* SSL connection using TLSv1.3 / TLS_AES_256_GCM_SHA384 / secp521r1 / id-ecPublicKey
* ALPN: server accepted h2
* Server certificate:
* subject: CN=blog.zeroplex.tw
* start date: Aug 7 04:01:59 2025 GMT
* expire date: Nov 5 04:01:58 2025 GMT
* subjectAltName: host "blog.zeroplex.tw" matched cert's "blog.zeroplex.tw"
* issuer: C=US; O=Let's Encrypt; CN=E5
* SSL certificate verify ok.
* Certificate level 0: Public key type EC/secp384r1 (384/192 Bits/secBits), signed using ecdsa-with-SHA384
* Certificate level 1: Public key type EC/secp384r1 (384/192 Bits/secBits), signed using sha256WithRSAEncryption
* Certificate level 2: Public key type RSA (4096/152 Bits/secBits), signed using sha256WithRSAEncryption
* using HTTP/2
* [HTTP/2] [1] OPENED stream for https://blog.zeroplex.tw/2020/11/01/benfords-law/
* [HTTP/2] [1] [:method: GET]
* [HTTP/2] [1] [:scheme: https]
* [HTTP/2] [1] [:authority: blog.zeroplex.tw]
* [HTTP/2] [1] [:path: /2020/11/01/benfords-law/]
* [HTTP/2] [1] [user-agent: curl/8.5.0]
* [HTTP/2] [1] [accept: */*]
* [HTTP/2] [1] [origin: https://zeroplex.tw]
> GET /2020/11/01/benfords-law/ HTTP/2
> Host: blog.zeroplex.tw
> User-Agent: curl/8.5.0
> Accept: */*
> Origin: https://zeroplex.twblog.zeroplex.tw:443 was resolved:處理 domain,這步驟相同TLSv1.3 (OUT), TLS handshake:SSL handshake,這步會透過 TLS 協定來建立加密連線,並且透過 ca-certificates.crt 根憑證來判斷網站的憑證是否正確到這邊,知道除了 URL 以外,header 和 body 都是建立加密連線以後才送出,所以敏感的資料最好是放在 header 和 body,避免被竊聽。
接下來討論 HTTPS 憑證。
HTTP 中的憑證,指的是 SSL certification。
HTTPS 中的憑證類似「執照」,需要經過審核、確認無誤以後才會頒發,而且會有期限,並不是隨便拿、隨便有的東西。
經過審核以後,憑證會被標示為「受信任」,這個時候,其他使用者連線到你的網站時,瀏覽器才會標示為安全 (綠色鑰匙,或沒有警告)。
標記為安全的憑證,一定是安全的嗎?並不是。
憑證已審核通過後,僅表示審核當下是被判定是沒問題的。若網站有漏洞,且漏洞被惡意人士利用,作為詐騙或是用來散佈惡意程式,通過回報來讓憑證管理機關了解該網站已有安全疑慮,主管機關會撤銷原本簽署的憑證 (徹照),使用者的瀏覽器便會警告該網站的憑證有問題。回報、到主管機關撤銷憑證之間,會有一段時間憑證仍然被標示為正常,這段時間就必須由使用者自己來判斷是否安全、可信任。
那標示為有問題的憑證,真的就一定有問題嗎?也不是。
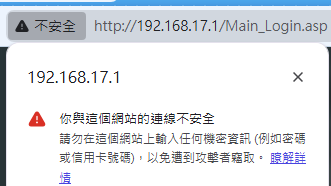
憑證被標示有問題,可能只是憑證沒有通過主管機關審核而已。若只是為了自己的伺服器與使用者之間,透過加密連線來保障內容不會被竊聽,可以自己產生的憑證不需要透過主管機關審核,常見的案例就是 wifi 分享器、伺服器設定頁面,都會走 HTTPS 加密連線,但是憑證都顯示為不安全 (沒有過審核)。
以下圖片,是 ASUS 無線網路分享器自己產生的憑證,被瀏覽器標示為不安全:
人權是大哉問,我對人權的了解程度還不適合來討論這個議題,不過有人提到了我要講一下。
台灣的憲法,保障「人民有秘密通訊之自由」,這是基本人權,和居住、安全一樣,是基本的權力,不是選擇性保障的權力。
所以不使用 HTTPS 而是使用 HTTP,指保障了電池使用時間 (處理器不需要加密、解密比較省電),反而讓使用者多了一個不安全的管道而已。
HTTPS 不代表一定安全,但是一定會比 HTTP 安全。使用 HTTPS 才能讓伺服器、使用者避開已知的問題。
ps1. 不知道作者會不會看到,覺得應該還是寫一下,如果是為了「安全」,你不應該使用 Internet Explore 當作範例,因為瀏覽器本身就不安全
ps2. 如果架網站只是為了從 Google 或 Facebook 等大公司取回自己的權力,那架網站其實只是假議題,公司掌握了超過半數的使用者,他們只要認定你有問題你就有可能讓你從網路上消失,再說你要怎麼確認你的網站不是跑在大公司的伺服器上、網路傳輸優先順序沒有被調低? (網路中立) 詳細內容請參考「數位帝國」(ISBN:9786267523230)
反串注意!
接觸 YAML 大概是因為遇到 docker 和 kubuernetes 的關係,因為設定檔都必須使用 YAML,然後受到各種荼毒。
先來看一下 spec。
YAML 目前支援常見的幾種資料型態:
100、-100、不同進位的表示法 0xC12.3015e+02、負無限 -.inf、以及非數字 .nantrue、falseJohn 、加上引號 "John" 或 'John'先到這邊即可,其他容器類型的陣列、物件這邊先不討論。
這邊先來看一下可能會遇到的問題這個描述:
Name: Zeroplex version: 3.2.9 stable: 3.2
這邊使用 Symfony\Component\Yaml 來 parse 上面的設定,結果為:
array(3) {
'Name' =>
string(8) "Zeroplex"
'version' =>
string(5) "3.2.9"
'stable' =>
double(3.2)
}
二個版本號,一個是字串,一個是數字。
為什麼會這樣?YAML 中並沒有規範怎麼樣的文字會應該是數字、什麼狀態是文字。也就是說如果字串沒有加上引號時,依照不同的 parser 實作方式,可能會有不同的結果。
這就是規範不明確導致的 undefine behaviour,最慘的是不同的 parser 實作方式不同,因此相同的設定檔使用不同的 parser 可能會被轉譯成不同的內容,而且無法誤測。
上述指示其中一個小問題,如果你想知道其他的問題,可以參考 The yaml document hell 這篇文章,設計不良讓大家都下地獄。
除了 YAML 以外,其實還有不少設計很好的語言,可以用來協助標示設定、狀態:
只因為 YAML 定義不明確,浪費幾個工作天除錯,真是浪費生命。
我接觸 PHP 蠻久了,大概從 5.1 還是 5.2 開始用到現在 8.4,避開了聽說很雷的 PHP 4,看著 PHP 引進新的功能,到現在社群開發出各種神奇的工具。
回顧過去一些事情,我覺得很重要的事情,不只可以了解 PHP 是什麼樣子程式語言,或許也可以協助判斷其他程式語言是否適合在你手上的專案使用。
就我所知,PHP 4 到 5 主要是支援物件導向,開始可以使用 class 來設計自己所需的功能,不用擔心 function name 和其他人的衝突。在這個時候,大家可以各自在網路上下載別人寫好的類別來使用,例如那個時候「藍色小舖」就有很多工程師分享自己實做的功能,例如 MySQL driver 之類的。
一些大型的專案仍保有這類的程式,像是 dolibarr ERP 的 /htdocs/core/class 目錄下,就有多個作者實做的 class。
在這個時候,功能比較複雜的專案可能會遇到類似的問題,我想要 require 新的 class 時,發現該 class 也有 require 其他的 class,如 dolibarr 的 fileupload.class.php:
<?php
/* Copyright (C) 2011-2022 Regis Houssin
* ....
*/
require_once DOL_DOCUMENT_ROOT.'/core/lib/files.lib.php';
require_once DOL_DOCUMENT_ROOT.'/core/lib/images.lib.php';
/**
* This class is used to manage file upload using ajax
*/
class FileUpload
{
在 FileUpload 中需要使用到 files 和 images 這二個類別。
若現有的專案,剛好有這二個類別時,會遇到類別名稱衝突,導致 require 失敗,導致 FileUpload 沒有辦法使用。這個問題其實和更早期 PHP 的狀況相同,大家各自實做自己的 function、和別人分享 function,卻又怕遇到相同的 function 名稱導致衝突。
為了解決 dependency (相依性、依賴關係) 問題,PHP 5.3 開始支援 namespace。
透過 namespace 功能,大家為 class 和 function 設定各自的 namespace,如:
<?php
namesace Zeroplex;
class FileUpload {
}
雖然 class 名稱相同,但只要在不同的 namespace 就不會導致衝突。
再故事往下之前提一下 autoload 功能,當 require 寫到手軟時,就開始有人開始想各種偷懶的方法了。
PHP 的 autoload 功能,允許使用者在建議物件時,針對自訂的邏輯,決定要做什麼事。所以這讓帶來幾個好處:
當這個功能合併使用時,就獲得合併技能「要使用時在 require」,不僅可以讓程式碼可讀性增加,也可以減少 disk I/O、記憶體使用量。
例如我透過 spl_autoload_register() 先定義好 require 規則:
<?php
spl_autoload_register(function ($className) {
$classInfo = explode('/', $className);
$namespace = $classInfo[0];
$className = $classInfo[1];
echo "namespace: " . $namespace . "\n";
echo "class name: " . $className . "\n";
require __DIR__ . "/library/" . $namespace . "/" . $className . ".php";
}
上述設定會自動將 Zeroplex/FileUploader 拆解成 namespace 和檔案名稱並 require,執行程式時會在 new 階段透過 autoloader 來決定要去哪裡 require 檔案:
<?php $uploader = new Zeroplex\FileUploader(); namespace: Zeroplex class name: FileUploader
在百家爭鳴寫 library 時,還會遇到一個問題:A 和 B library 都需要用到 C library,但 A library 中任何版本的 C library 都可,而 B library 則需要 C library 的最新版。這樣開發程式時,就還需要考慮到底要使用 C library 的哪一個版本。
於是 composer 就出現了。composer 是 dependency management,會自動尋找專案中各 library 可正確運作的版本。
時間往後走一段時間, 來到 PHP 7。
PHP 7 做的最大改變,是大幅改寫直譯器,讓效能大幅提升,而且不只是快一點點而已,是快了 100%。以前為了讓 PHP 程式跑得更快,Facebook 開發了 hhvm,現在用不到了。
若想知道為什麼效能可以快這麼多,可以參考 Nikita Popov (PHP 核心工程師之一) 的簡報:PHP 7 – What changed internally?。或是聽他的演講:
除了效能以外,PHP 在此時也慢慢的提供一些資料型態的定義、檢查功能,像是在撰寫 function 時可以定義 argument 的資料型態 (type hint),除了 scalar type 也開始支援使用者自訂 class 的支援。
這些支援,讓原本是 dynamic typing 的 PHP 可以多一些檢查,程式的可讀性和穩定性上都有改善。
PHP 7 到 8 我打算很不負責任得什麼都不說直接跳過 XD
這邊列出一些有趣的專案: